 Header image by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Header image by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Hackathons force software systems into extreme conditions: limited time, incomplete guarantees, and architectural decisions that must work immediately.
In just 48 hours, during the Sinhgad Hackathon 2026, we — Ary and I — built ProofVote, a secure, decentralized voting system implemented entirely in C++. (Our work can be viewed on GitHub.)
📜 Sinhgad Hackathon 2026 Certificate
Official participation certificate issued by the hackathon organizers.
Rather than treating voting as a simple database problem, we approached it as a distributed trust problem:
- Votes must remain immutable
- Participants must agree on state
- No single machine should control election integrity
This naturally led us to adopt a permissioned blockchain architecture combined with a Byzantine Fault Tolerant consensus engine. The result is a prototype capable of executing complete elections under replicated consensus at the network level, ensuring that correctness does not rely on trusting a single authority.
Why Traditional Electronic Voting Is Problematic
Most electronic voting systems rely on centralized infrastructure. This introduces structural weaknesses:
- Single points of failure
- Risk of tampering
- Opaque vote recording
- Dependence on institutional trust
A centralized server can always become the weakest link. ProofVote eliminates this dependency by distributing trust across multiple validator nodes, forcing a majority of replicas to agree before any state changes are considered valid.
Why a Permissioned Blockchain
Public blockchains optimize for open participation, but voting systems require controlled membership. Only authorized participants should be able to:
- Register
- Create elections
- Submit votes
- Query final state
ProofVote uses a permissioned blockchain, where each committed vote becomes part of an immutable distributed ledger, and validator nodes remain known participants rather than anonymous miners.
This design reduces unnecessary overhead while preserving auditability and verifiability.
The Core Architecture of ProofVote
ProofVote was designed around two major subsystems:
- Consensus Engine — BigBFT
- Network Layer — Reactor Pattern
These two layers address distinct concerns:
- Consensus determines which state is valid.
- Networking determines how messages move efficiently.
This separation proved essential for both correctness and performance during implementation.
In addition, OpenSSL is used for all cryptographic operations, including signing and verifying blocks, generating quorum certificates, and securing the network. This ensures that all consensus messages and votes are authenticated and tamper-proof.
The project was developed entirely in C++ without external runtime dependencies, and the build process is managed using Premake, which generates platform-specific build scripts for compilation. While development was primarily done on Linux, ProofVote was later tested on macOS and Windows to ensure successful compilation and cross-platform portability. This setup allows ProofVote to remain lightweight, portable, and easy to integrate into diverse environments.
BigBFT: Consensus Under Adversarial Assumptions
The core consistency mechanism of ProofVote is BigBFT, a multi-leader Byzantine Fault Tolerant (BFT) consensus protocol that guarantees agreement even when a subset of validators behaves maliciously or fails.
What is Byzantine Fault Tolerance (BFT) and Why It Matters
Byzantine Fault Tolerance (BFT) is a property of distributed systems that enables them to reach consensus even when some participants act arbitrarily or maliciously. Validators in a BFT system must agree on a single state or sequence of actions despite crashes, network delays, or coordinated attacks.
BFT is critical for ProofVote because trust cannot be assumed: participants may act dishonestly or fail unpredictably. Without BFT, a malicious or faulty validator could disrupt consensus, reorder votes, or prevent operations from finalizing, undermining the integrity of the system.
By using BFT, ProofVote ensures:
- Safety — No two correct validators ever commit conflicting results.
- Liveness — Honest client requests eventually make progress and are committed.
- Resilience under attack — The system tolerates up to F faulty validators out of N without compromising correctness.
BigBFT was chosen as the consensus protocol for ProofVote not only because it provides high throughput, strong safety guarantees, and robustness under adversarial conditions — all essential for an election system where every vote must be reliably recorded and verifiable — but also because it presented an interesting implementation challenge.
Understanding BigBFT was particularly difficult, as the original paper is the only detailed resource available. Its design, including multi-leader pipelining and across-round commitment, is intricate and subtle, requiring careful study to implement correctly. Readers interested in the full technical specification can consult the original paper in the “Further Reading” section at the end of this post.
How BigBFT Works
BigBFT operates in a network of
N validators, of which up to F may be faulty or behave maliciously.
These parameters define the system’s fault tolerance and quorum requirements:
to ensure safety, BigBFT
requires signatures or votes from at least N − F correct validators to
certify a block.
Every validator executes the same deterministic state machine, ensuring that all correct replicas apply proposals in an identical, predictable order. This determinism is crucial for maintaining safety across the system.
Unlike traditional single-leader BFT protocols, BigBFT allows multiple leaders to propose blocks concurrently within the same round. To distribute responsibility fairly, the coordinator role rotates in a round-robin fashion among leaders each round. This approach balances load, reduces the risk of bottlenecks, and ensures that no single node becomes a persistent target.
BigBFT also decouples proof generation from final commitment: one round produces quorum proofs for candidate blocks, and the subsequent round uses these proofs to finalize and commit the replicated state. This across-round pipelining increases efficiency without sacrificing determinism or safety, making the protocol robust under adversarial conditions.
Coordination Phase — Round-Robin Sequencing
The coordination phase ensures deterministic sequence assignment and mitigates leader bottlenecks by executing in parallel with the previous round’s consensus.
In each round, the following steps occur:
The coordinator, selected in a round-robin fashion, increments the round number
rand initiates the new round.The coordinator constructs a round-change message:
$$ RoundMsg \langle RChange, Z, r, L \rangle $$
where:
RChangedenotes the round-change message type;Zspecifies the sequence number partition assigned to each leader; $$ Z = \lbrace z_i \mid L_i \in L \rbrace $$ris the round number;Lis the current set of leaders.
The coordinator broadcasts
RoundMsgto all leaders:$$ RoundMsg \langle RChange, Z, r, L \rangle \rightarrow { L_1, L_2, \dots, L_N } $$
Upon receiving
RoundMsg, each leaderL_iperforms the following:- Verifies the message against its local state,
- Signs an acknowledgment using its secret key
sk_ito produce
$$ Ack_i = \sigma_i(RChange, r, L_i) $$
- Returns
Ack_ito the coordinator.
Once the coordinator collects acknowledgments from at least
N − Fleaders, it aggregates them into the round quorum certificate:$$ RoundQC_r = \langle r, L, agg_{qc} \rangle $$
where:
ris the round number;Lis the set of leaders whose acknowledgments were received;agg_{qc}is the aggregated signature of allAckfor round.
The coordinator then broadcasts
RoundQC_rto all leaders:$$ RoundQC_r \rightarrow \lbrace L_1, L_2, \dots, L_N \rbrace $$
This RoundQC confirms that the leaders have received and acknowledged the round-change, and simultaneously assigns sequence number partitions for the upcoming round. Once the coordination phase concludes, all leaders are prepared to wait for client requests with their assigned ranges, ensuring deterministic ordering and parallel proposal generation.
Step 1 — Client Dissemination
A client does not submit its operation to a single leader.
Instead, the client first constructs a request message, denoted by req, and
broadcasts it to F + 1 leaders, including the coordinator.
The request is represented as:
$$ \text{req} \langle Request,\ t,\ O,\ id \rangle $$
where:
Requestidentifies the message type,tis the timestamp associated with the request,Odenotes the client operation,ididentifies the client issuing the request.
The operation O corresponds to the action that the client wishes to execute
in the replicated election state machine, such as registering a member,
creating an election, or submitting a vote.
Broadcasting to F + 1 leaders ensures that even if some leaders fail or
become unavailable, at least one correct proposer receives the request and can
inject it into the consensus pipeline.
Formally:
$$ \mathrm{req} \rightarrow \lbrace L_1,L_2,\dots,L_{F+1} \rbrace $$
where L_i denotes a leader node.
Only after leader-side verification does the request become an ordered proposal.
At that point, the client operation is encapsulated into a candidate block
denoted by B_i, which enters the next consensus phase.
Step 2 — Proposal Verification and Prepare Formation
Upon receiving a client request, each leader performs local verification before encapsulating the validated operation into an ordered candidate block.
This verification stage includes:
- Validating block structure;
- Checking transaction integrity;
- Assigning a sequence number.
After verification, the leader creates a prepare message, denoted by prep,
which carries both the newly proposed block and the proof generated in the
previous consensus round.
The prepare message is represented as:
$$ \text{prep} \langle Proposal,\ AggQC_{r-1},\ B_i \rangle $$
where:
Proposalidentifies the message type;AggQC_{r-1}is the aggregated quorum certificate produced in roundr - 1;B_iis the newly proposed block for roundr.
The aggregated quorum certificate AggQC_{r-1} contains the quorum proofs that
justify commitment of previous-round blocks.
Its inclusion is fundamental because BigBFT does not commit blocks immediately after proposal formation.
Instead, commitment is deferred across rounds: proof generated in round r - 1
is attached to proposals in round r, enabling pipelined commitment.
This creates the transition:
$$ \text{req} \rightarrow B_i \rightarrow \text{prep} $$
where leader-side proposal construction and proof attachment become part of the same deterministic consensus stage.
Step 3 — Prepare Broadcast
Each leader broadcasts its prepare message to all other leaders.
$$ \mathrm{prep}_i \rightarrow \lbrace L_1,L_2,\dots,L_N \rbrace $$
where prep_i denotes the prepare message emitted by leader L_i.
At this stage, multiple leaders may propose blocks in parallel.
This means several candidate blocks may coexist during the same round without violating safety, since ordering remains governed by quorum formation.
Parallel proposals improve throughput while maintaining replicated consistency.
Step 4 — Vote Generation
Upon receiving prepare messages, each leader validates the candidate proposals and inspects the aggregated quorum certificate attached to the message.
If AggQC_{r-1} is valid, blocks proposed in the previous round become
eligible for commitment.
After successful validation, each leader independently produces one cryptographic signature for every valid proposal received during the current round.
The resulting vote message is denoted by:
$$ \text{vote} \langle Vote,\ V,\ round \rangle $$
where:
Voteidentifies the message type;Vdenotes the set of signatures generated by the leader for all valid proposals in the current round;roundidentifies the consensus round in which the vote was produced.
For a leader L_i, the vote set V_i generated in round r is expressed as:
$$ V_i = \lbrace \sigma_i(B_i)\mid B_i\in \mathcal{P}_r \rbrace $$
where each signature \sigma_i(B_i) represents validator L_i’s approval of
block B_i.
For example:
L1: { σ1(B10), σ1(B11), σ1(B12) }
L2: { σ2(B10), σ2(B11), σ2(B12) }
L3: { σ3(B10), σ3(B11), σ3(B12) }
This means that each leader emits one signature per valid proposal, and the set of signatures generated locally becomes the vote payload transmitted to the other leaders.
Formally, vote generation extends the protocol flow as:
$$ \text{req} \rightarrow \text{prep} \rightarrow \text{vote} $$
where prepare validation produces cryptographic approval for every accepted proposal.
Step 5 — Quorum Certificate Formation
A quorum certificate is formed only when signatures satisfy:
$$ |QC(B_i)| \ge N-F $$
where quorum certificate QC for block B_i is defined as:
$$ QC(B_i) = \lbrace \sigma_i(B_i)\mid L_i\in Q_r \rbrace $$
For example:
QC(B10) = { σ1(B10), σ2(B10), σ3(B10) }
QC(B11) = { σ1(B11), σ2(B11), σ3(B11) }
QC(B12) = { σ1(B12), σ2(B12), σ3(B12) }
Each quorum certificate proves that a sufficient number of validators accepted the corresponding proposal, making the block eligible for later commitment.
Because multiple blocks may be certified during the same round, all quorum
certificates produced in round r are aggregated into a single structure:
$$ AggQC_r = \lbrace QC(B_i)\mid B_i\in \mathcal{P}_r \rbrace $$
The aggregated certificate is then attached to prepare messages in the next round, enabling pipelined commitment across rounds.
Step 6 — Across-Rounds Pipelined Commitment
Commitment occurs only in round r + 1.
When leaders receive new prepare messages carrying a valid aggregated quorum
certificate AggQC_r, the blocks certified in round r satisfy the conditions
for deterministic commitment.
At this stage, each leader verifies that the aggregated certificate proves quorum for the previous-round proposals and then commits the corresponding blocks to the local replicated state machine.
Formally, commitment is represented as:
$$ Commit_{r+1}(B_i) $$
where block B_i becomes permanently part of the replicated ledger during
roundr + 1.
After commitment, the leader emits a reply message to the client, denoted by:
$$ rep \langle Reply,\ r,\ t,\ L \rangle $$
where:
Replyidentifies the message type;rdenotes the consensus round in which commitment was finalized;tidentifies the associated client request;Lidentifies the leader issuing the confirmation.
The reply confirms that the corresponding client operation has successfully passed consensus and has been committed by the validator.
This creates a pipelined execution structure:
- round
rproduces quorum proof; - round
r + 1finalizes state.
Formally, the protocol flow is extended as:
$$ \text{req} \rightarrow \text{prep} \rightarrow \text{vote} \rightarrow QC(B_i) \rightarrow AggQC_r \rightarrow Commit_{r+1}(B_i) \rightarrow rep $$
After a sufficient number of N − F vote sets have been collected, the
coordination phase runs again, incrementing the round number and assigning
new sequence partitions to leaders for the next round.
This mechanism is what we define as across-rounds pipelining. By overlapping proof generation, commitment, and coordination across consecutive rounds, BigBFT improves throughput while maintaining deterministic safety and fairness in sequence assignment.
Why This Matters
The practical consequence is simple:
- No vote becomes official unless enough replicas agree and quorum proof survives into the next round.
This is what transforms storage into trust. In ProofVote, consensus is not merely an ordering primitive — it is the mechanism that turns replicated execution into election legitimacy.
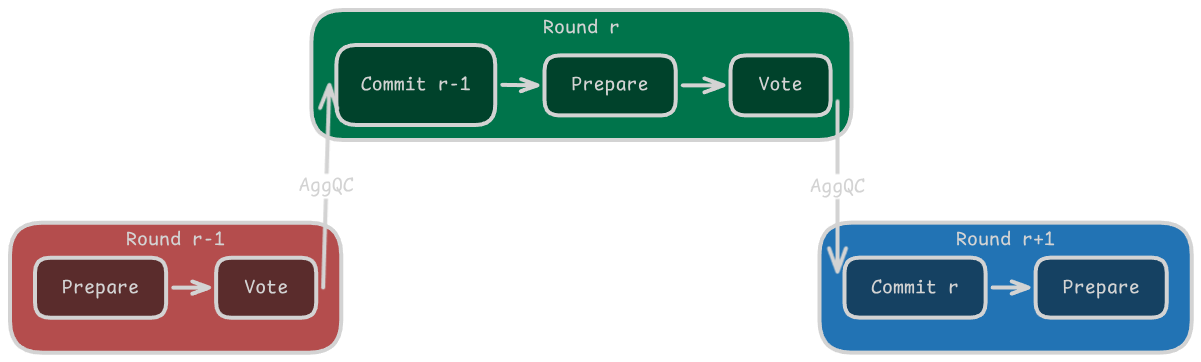 BigBFT Pipeline by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
BigBFT Pipeline by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Reactor Pattern: Eliminating Blocking in Network Operations
In a distributed consensus system, the reliability and timeliness of message delivery are as critical as the consensus protocol itself. Inefficient networking can easily become the bottleneck, negating the benefits of advanced consensus mechanisms like BigBFT.
Limitations of Traditional Socket Handling
A conventional approach to networking in C++ involves using blocking sockets, where each connection is handled by a dedicated thread:
- A thread calls
recv()to wait for incoming data; - The thread is blocked until data arrives or a timeout occurs;
- Each connection requires a separate thread, which incurs context-switching overhead and increases memory usage;
Formally, for N connections, the system must maintain roughly O(N) threads.
As N grows, the probability of thread contention, scheduling delays, and
excessive memory usage also grows:
$$ \text{Cost} * {\text{blocking}} \sim O(N \cdot T * \text{thread}) $$
where T_\text{thread} accounts for thread scheduling and stack overhead.
This design is not suitable for high-throughput, low-latency consensus, where hundreds of validators may communicate simultaneously.
The Reactor Pattern Solution
To overcome these limitations, ProofVote implements networking using the Reactor Pattern. The core idea is to decouple event detection from event handling, allowing a single thread (or a small pool) to manage multiple connections efficiently.
The reactor maintains a central event loop, monitoring:
- Incoming messages (e.g.,
recv()ready) - Outgoing writes (e.g.,
send()ready) - Connection events (e.g., new connections, closures)
Instead of blocking, each network event triggers a callback associated with the connection. For example, if a leader receives a prepare message, the event loop invokes the corresponding handler:
$$ \text{onEvent}(E) \longrightarrow \text{handleMessage}(E) $$
where (E) represents an event such as MessageReceived or ConnectionClosed.
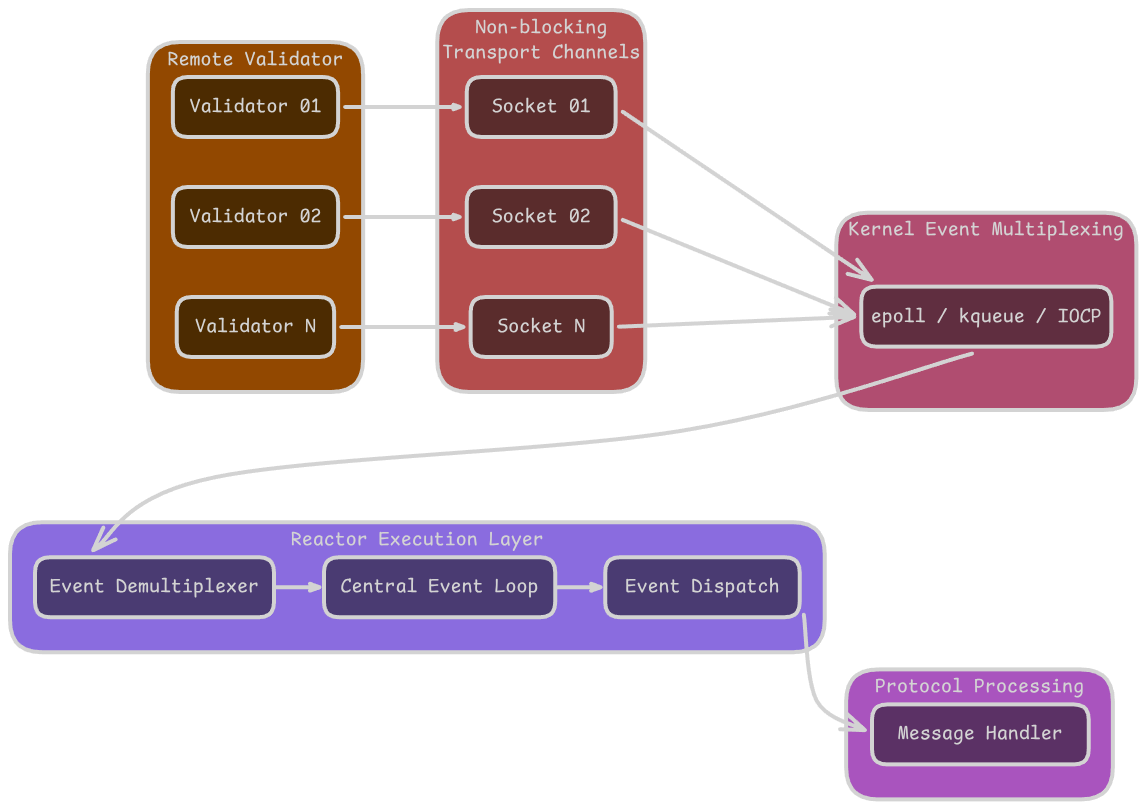 Reactor Pattern Diagram by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Reactor Pattern Diagram by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Advantages of the Reactor Pattern in ProofVote
This design provides several key benefits:
- Scalable Communication – Hundreds of validators can communicate simultaneously without spawning a thread per connection.
- Lower Coordination Overhead – The event loop naturally sequences message handling, reducing contention between threads.
- Clean Protocol Separation – Protocol logic (consensus, quorum validation, vote generation) is decoupled from low-level socket management, improving modularity and maintainability.
Formally, the event-driven cost scales sublinearly with the number of connections:
$$ \text{Cost}_{\text{reactor}} \sim O(1) \ \text{or}\ O(\log{N}) \quad \text{per event loop iteration} $$
depending on the underlying OS mechanism (e.g., epoll, kqueue, or IOCP).
By adopting the Reactor Pattern, ProofVote ensures that networking does not block consensus progress, even under high load. In distributed systems, the design of the event architecture can be as important as the consensus protocol itself, because timely, non-blocking communication directly impacts safety, liveness, and overall throughput.
Election Operations as Blockchain Transactions
ProofVote models election actions as transactions. The case study implemented during the hackathon included:
- Member registration
- Election creation
- Candidate definition
- Vote submission
- Election query
This means the blockchain does not merely store votes. It stores the full election lifecycle. That makes the ledger a state machine rather than a passive archive.
The University Election Case Study
To validate the architecture beyond synthetic tests, we executed a university rector election workflow. The client node performed:
- Registration of eligible members;
- Election creation;
- Vote submission;
- Result retrieval through sending a
QUERY ELECTION STATUSrequest.
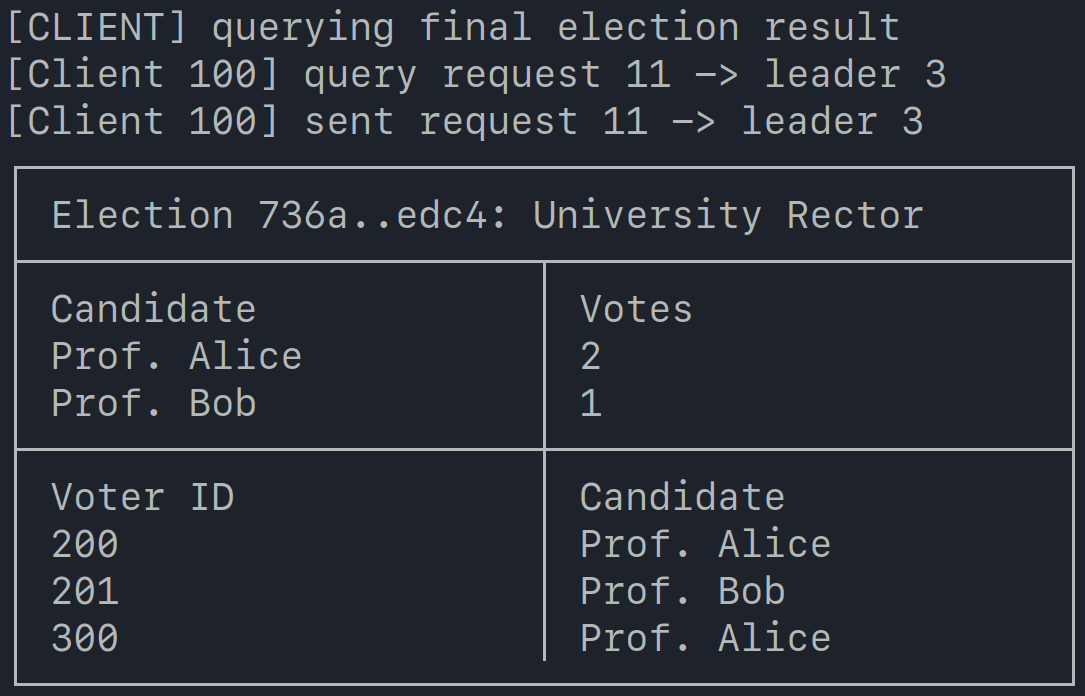 Case Stydy Demonstration by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Case Stydy Demonstration by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
This transformed ProofVote from infrastructure prototype into a complete end-to-end election experiment. That matters because many blockchain prototypes stop before real workflow validation.
Experimental Results
To assess the operational behavior of the prototype under sustained consensus load, a controlled benchmark was executed using the minimal Byzantine fault tolerant deployment required by the BigBFT protocol.
Experimental Setup
The evaluation environment consisted of:
- 4 validator replicas, satisfying the
3f + 1replication requirement; - 1 client node responsible for sequential transaction submission;
- 1000 submitted transactions under continuous request flow.
All validator processes executed the full consensus pipeline, including proposal reception, vote generation, quorum validation, and commit confirmation.
A fixed 50 ms inter-request delay was introduced at the client layer between consecutive submissions. This delay was necessary because, although the network layer uses a Reactor-based non-blocking architecture, the current transport implementation does not yet include an internal asynchronous message queue. As a result, the TLS communication layer could not reliably sustain bursts of requests below this interval without causing socket backpressure or partial write contention.
Formally, the effective client submission rate was constrained by:
$$ r_{client} = \frac{1}{50\ ms} = 20\ \text{requests/s} $$
This value therefore represents the practical upper bound imposed by the current transport implementation rather than the theoretical consensus limit of the protocol itself.
The primary objective of the benchmark was to measure:
- Sustained throughput;
- End-to-end commit latency;
- Execution stability under continuous consensus activity.
Benchmark Summary
| Metric | Observed Value |
|---|---|
| Submitted transactions | 1000 |
| Completed transactions | 1000 / 1001 |
| Validator replicas | 4 |
| Client nodes | 1 |
| Total execution time | 55.12 s |
| Throughput | 18.09 TPS |
Throughput was computed as:
$$ \mathrm{TPS} = \frac{1000}{55.12} \approx 18.09 $$
Latency Distribution
Observed latency statistics were:
| Statistic | Latency |
|---|---|
| Minimum | 51.56 ms |
| Average | 125.23 ms |
| Maximum | 223.76 ms |
| p50 | 124.81 ms |
| p95 | 190.82 ms |
| p99 | 197.44 ms |
A simplified latency distribution is shown below:
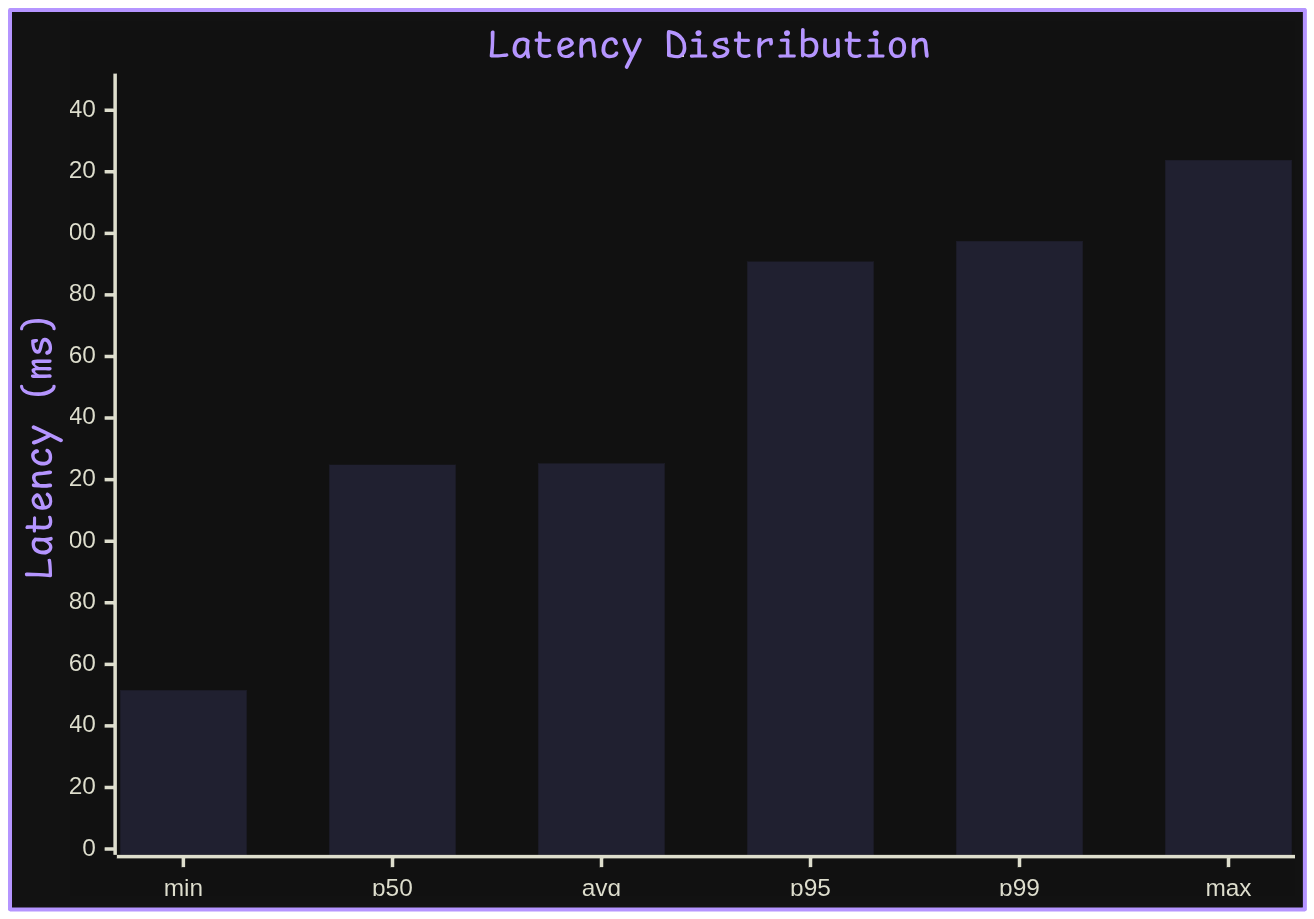 Latency Distribution by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
Latency Distribution by gabrielzschmitz,
licensed under Creative Commons 4.0 Attribution license.
The latency profile indicates relatively stable commit completion under continuous load, with median and average values remaining closely aligned, suggesting limited variance in steady-state execution.
Performance Interpretation
The benchmark demonstrates that consensus remained stable across all validator replicas throughout the entire execution interval.
Observed latency remained centered near 125 ms, indicating predictable consensus completion despite repeated cryptographic verification and multiple network round exchanges.
Current throughput is primarily constrained by implementation-level overhead, including:
- Consensus coordination across replicas;
- Digital signature generation and verification;
- TLS transport serialization;
- Request lifecycle management;
- Absence of asynchronous outbound buffering.
The measured throughput should therefore not be interpreted as the protocol’s theoretical upper bound, but rather as the current limit of the prototype’s transport pipeline.
What 48 Hours Actually Teaches
The most immediate lesson from the hackathon was clear:
Designing a blockchain is conceptually straightforward, but operationalizing it is profoundly challenging.
The engineering difficulty emerges in concrete questions:
- How does system state evolve deterministically under concurrency?
- When is quorum sufficient to safely commit a block?
- How are failures and malicious behaviors tolerated?
- How are client requests serialized to prevent conflicts?
- How do you implement real-world, low-latency networking?
Voting systems amplify these challenges because they encode political trust into protocol logic. Every design decision carries implications for correctness, safety, and auditability — and it all becomes apparent very quickly under load and time constraints.
Conclusion
ProofVote was implemented in just 48 hours, but its true value lies in the architectural lessons it embodies.
It’s worth noting that, although the coding sprint lasted only two days, we were invited to the hackathon two weeks in advance. During that period, we submitted our proposal for a decentralized blockchain-based voting system, which had to be accepted by the organizers. In that window, we studied and prepared the necessary concepts — from BFT consensus to cryptographic verification and event-driven networking — without writing any of the code that ultimately formed the project at submission. This preparation was essential to ensure that the 48-hour coding period could focus entirely on implementation rather than research.
The project demonstrates how distributed trust, cryptographic verification, and replicated state can be integrated into a single, coherent system. A voting platform is not merely an application; it is a protocol that enforces legitimacy, ensuring that every action is provable, ordered, and verifiable.
Implementing ProofVote entirely in C++ made each layer of the system explicit: from low-level networking and event handling, through consensus logic, to cryptographic guarantees. Every design choice is visible, tested, and accountable — a rare opportunity to see distributed trust unfold in practice.
Further Reading
Miguel Castro & Barbara Liskov (1999) “Practical Byzantine Fault Tolerance,” in OSDI ’99. Introduces PBFT, the foundational BFT consensus protocol that inspired many modern multi-leader BFT systems. 📄 Read PDF
Cesar Ghiani, et al. (2021) “BigBFT: Scaling Byzantine Fault-Tolerant Consensus with Multi-Leader Pipelines,” IEEE Trans. Dependable Secure Comput. Detailed description of BigBFT, the protocol implemented in ProofVote, including multi-leader pipelining and across-round commitment. 📄 Read PDF
Leslie Lamport (1998) “The Part-Time Parliament,” ACM Trans. Comput. Syst. 16(2): 133–169. Introduces the Paxos algorithm, a cornerstone of replicated state machines and deterministic consensus. 📄 Read PDF
Nancy Lynch (1996) “Distributed Algorithms,” Morgan Kaufmann. Comprehensive textbook on distributed systems, including consensus, fault tolerance, and event-driven architectures. 📄 Book Info
Douglas C. Schmidt, Michael Stal, Hans Rohnert, Frank Buschmann (2000) “Pattern-Oriented Software Architecture, Volume 2: Patterns for Concurrent and Networked Objects,” Addison-Wesley. Explains the Reactor Pattern and event-driven design, which underpins ProofVote’s scalable networking layer. 📄 Book Info
Permissioned Blockchains for Real World Applications Examines the evolution from public blockchain systems toward private, permissioned distributed ledgers, emphasizing governance, consortium participation, and real-world institutional deployment. Particularly relevant to ProofVote because it frames permissioned blockchain not merely as a cryptocurrency derivative, but as an infrastructure for trusted distributed coordination in controlled environments. 📄 Thesis
OpenSSL Project (2026) “Cryptography and SSL/TLS Toolkit.” Documentation and reference for using OpenSSL in cryptographic operations, including signing, verification, and certificate management. 📄 OpenSSL Docs
Philippe Flajolet & Robert Sedgewick (2009) “Analytic Combinatorics,” Cambridge University Press. Mathematical background for understanding probabilistic behavior in distributed protocols and message handling under high concurrency. 📄 Book Info
I hope this post gives you a clear window into what building a secure, distributed system really entails. If you’re curious about consensus, cryptography, or just want to see how theory turns into working C++ code, there’s plenty here to explore and experiment with yourself.
- gabrielzschmitz